1. 如何处理href不是链接而是javascript脚本的情况
新浪的博客分页

这些href的值是javascript脚本

如何定位这些标签,并触发换页呢。
之前做爬虫的做法是,定位到next,然后不断点next,直到找不到next为止。
所以目前的方案是:
- 找到网页的全部a link标签
- 如果link标签不是有效的href,检查其文本内容是不是"下一页“ ’next'等
- 如果是,点触发点击,再循环遍历新网页的Link,
- 直到找不到next为止
2. 截的图有被一些固定标题挡住

当截取一个很长的网页时,如果页面上有固定的页眉、导航栏或工具条(通常使用 position: fixed 或 position: sticky CSS属性),截图工具在“滚动”页面时,这个固定的元素会一直停留在原位,导致它出现在最终长图的中间位置。为了解决这个问题,我将在截图前,通过执行一小段JavaScript代码,暂时隐藏掉页面上所有固定的和粘性的元素。这样,它们就不会干扰长截图的生成了。
3. qq空间分页点击搞出死循环
之前分页检查的关键字如下:
yaml
const NEXT_EXACT = /^(下一页|下一頁|下页|更多|Next|More|Older|next|more|older|加载更多|點擊查看更多|下一張|下一张|下一章)\s*(>|>|»)?\s*$/i;可qq空间菜单项有一个固定的 “更多”

导致一直触发分页点击
看来之种分页检查,不能默认开放,检查的规则还是要用户自己输入 才行
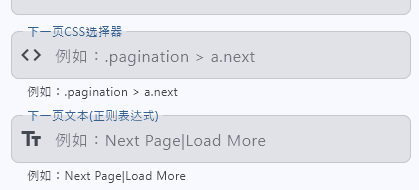
配置项又变多了
4. qq空间中的链接取不到
4.1 现象

通过js获取全文的href没找到对应的
js
const anchors = Array.from(document.querySelectorAll("a[href]")).map(a=>{
return {
href: a.href,
protocol: a.protocol,
text: a.textContent || '',
};
});有点奇怪,看了一下标签,是正常的
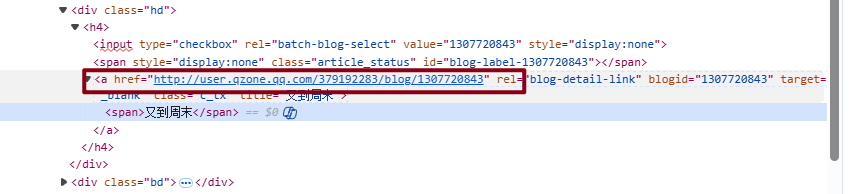
4.2 原因
因为这个链接是 在一个子frame下
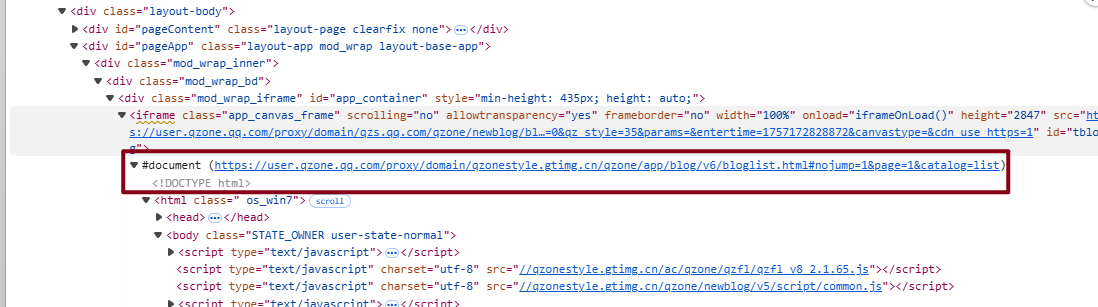
只 能遍历全部iframe