1. 一、新增:单条微博备份
现在可以直接输入单条微博链接发起备份,例如 weibo.com 或 m.weibo.cn/detail 形式的地址。程序会自动解析微博 ID;如果是 weibo.com 链接,也会解析账号 ID。
- 支持示例:weibo.com/8485906707/5306870604761569。
- 支持示例:m.weibo.cn/detail/5306870604761569。
- 单条微博任务不再需要时间范围和数量限制。
- 单条微博仍支持随机等待设置,避免高频请求。
1.1 二、新增:评论和转发备份
单条微博备份时,可以同时保存评论和转发。生成的 HTML 中,评论与转发以两个 Tab 展示,用户可以在同一个微博页面里快速切换查看。
配图:评论与转发 Tab,评论 4748,转发 3307。
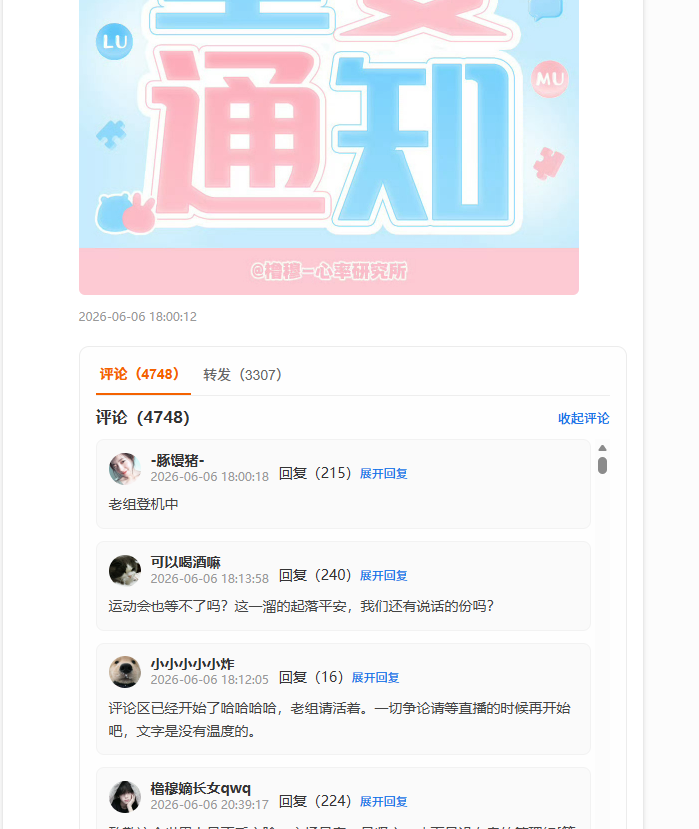
- 评论支持一级评论和子评论。
- 转发以类似评论的列表形式保存,包含用户头像、昵称、时间和转发内容。
- 评论和转发可以分别展开或收起,互不影响。
1.2 三、优化:大数据量页面不再卡顿
评论和转发数量较大时,原来的 HTML 会一次性渲染所有 DOM,打开页面容易卡顿。这次接入了 virtual scroll,只渲染当前可见区域附近的数据。
配图:转发列表虚拟滚动,转发 3307,页面仍可流畅滚动。
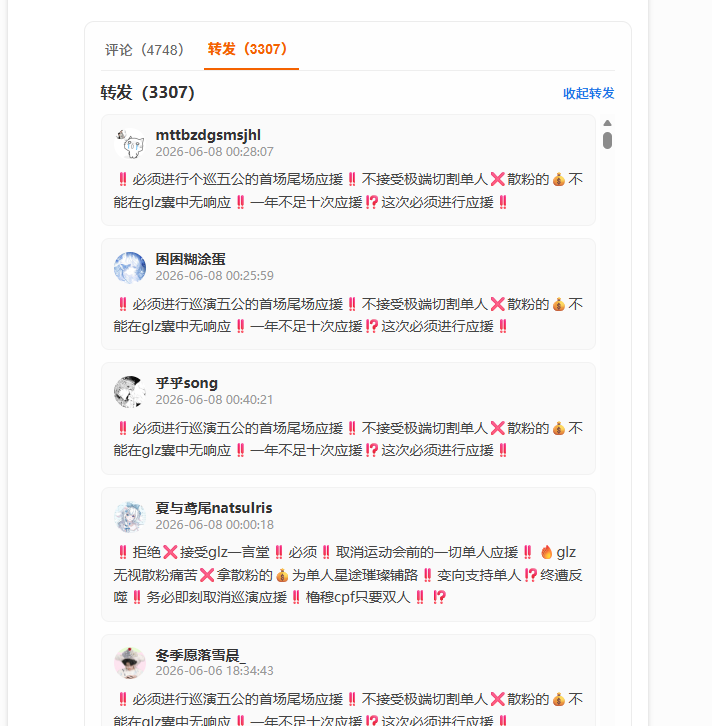
- 评论、转发数量超过阈值后自动启用虚拟滚动。
- 列表滚动时动态渲染可见项,降低浏览器 DOM 压力。
- 展开评论或切换 Tab 后,会按当前容器重新初始化列表。
1.3 四、优化:评论采集数量大幅提升
Weibo M 默认评论接口容易停留在热评流,导致采集数量和官方显示差距很大。这次将一级评论采集切换到时间流,并修复断点恢复时误判完成的问题。
配图:3 万+ 评论采集验证,评论 37360。
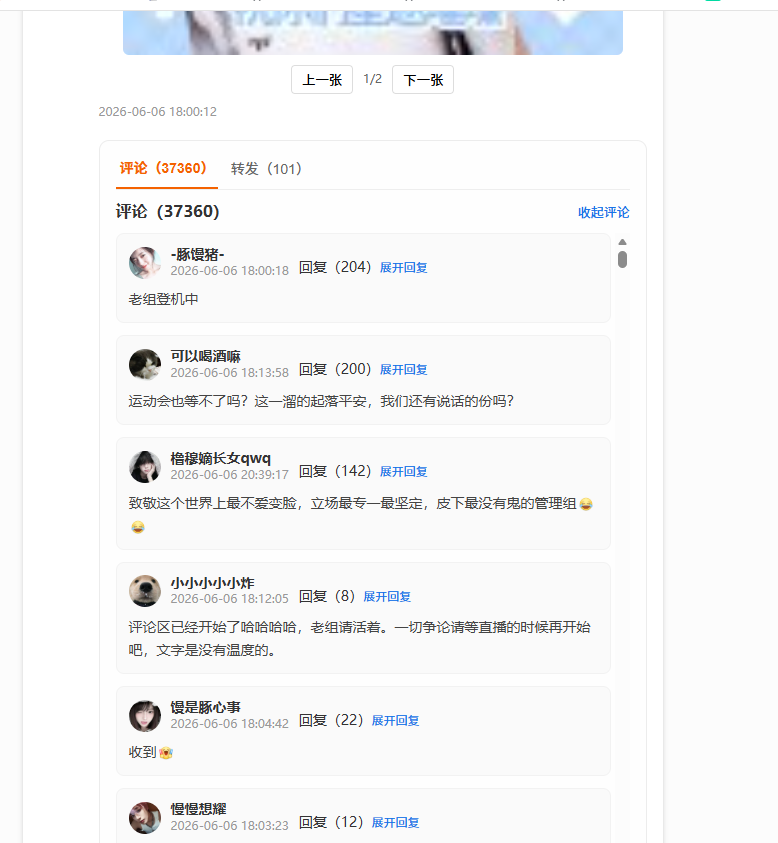
- Weibo M 评论从热评流切换到时间流,减少“几百条后无下一页”的情况。
- 评论采集会输出本地数量、官方数量和退出原因,方便判断接口是否提前结束。
- 当本地数量明显小于官方数量时,不再把任务直接标记完成,后续可以继续尝试。
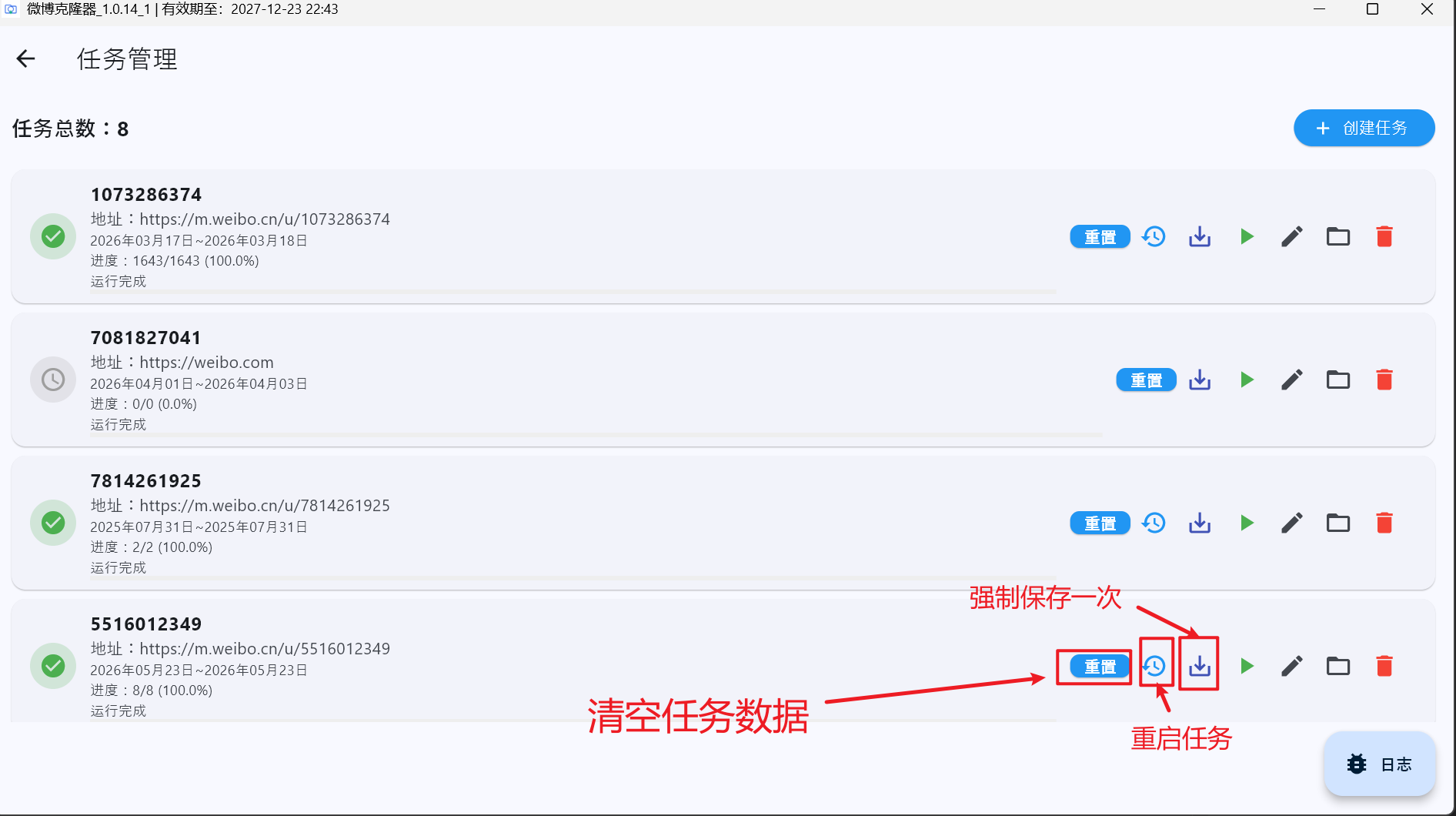
1.4 五、新增:断点续采和强制保存
评论、子评论、转发采集过程中都会保存断点。任务暂停、接口异常或手动中断后,可以从上一次位置继续,避免重新从 0 开始。
- 评论分页、转发分页、子评论节点都会记录进度。
- 节点的子评论全部采集完成后,会标记为已完成,恢复时不用重复遍历。
- 新增强制保存入口,可以把当前 checkpoint 中已经采集到的数据立即重建为 HTML。
- 即使任务状态已经是完成,也可以通过恢复可运行状态或强制保存继续处理已有数据。
1.5 六、优化:接口异常和假空页处理
微博接口会偶发返回空数据、ok=0、游标不推进等异常。现在采集逻辑会更谨慎地判断退出原因,避免把临时错误当成真正末页。
- 转发接口未到 maxPage 时返回 ok=0,会保存当前页断点并退避重试。
- 评论游标重复或循环时,不再直接标记整个互动采集完成。
- 空页、数量不足、游标循环、HTTP 异常都会记录明确日志。
- 需要验证码或接口返回异常时,会保存断点并暂停,方便用户验证后继续。
1.6 七、优化:HTML 输出稳定性
这次还修复了多个保存和展示细节,避免大任务在最后生成 HTML 时出错。
- 修复移动端正文中的 HTML 标签裸露问题,例如 a href 和 br 标签不会再直接显示在页面里。
- 修复强制保存时文件名过长或包含非法字符导致保存失败的问题。
- 修复展开评论时递归展开所有层级的问题,现在只展开当前层级。
- 评论与转发的 HTML 结构统一,后续继续扩展互动数据会更容易。