主题
2/1/2026
新浪博客为例,10年前,博客很火的时候,我也有在那里留下了一些日记
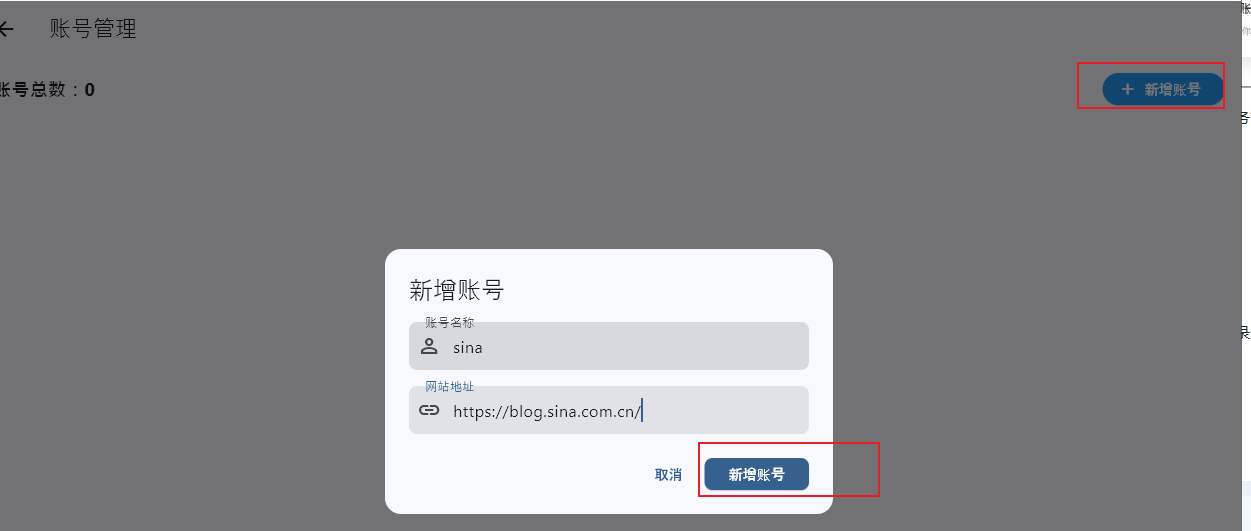
目前新浪的博客只能自己可见,需要登录
初始是未登录状态
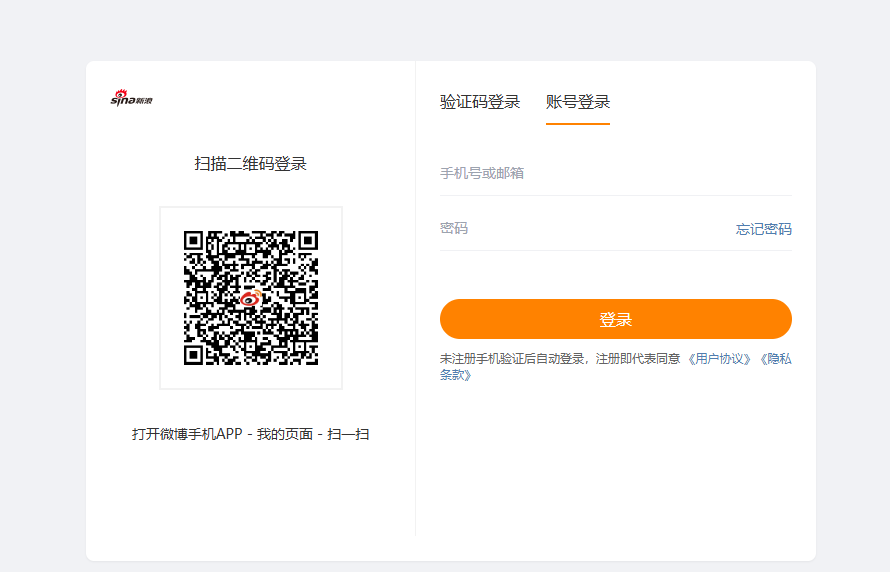
会打开浏览器,
在浏览器中登录你的账号
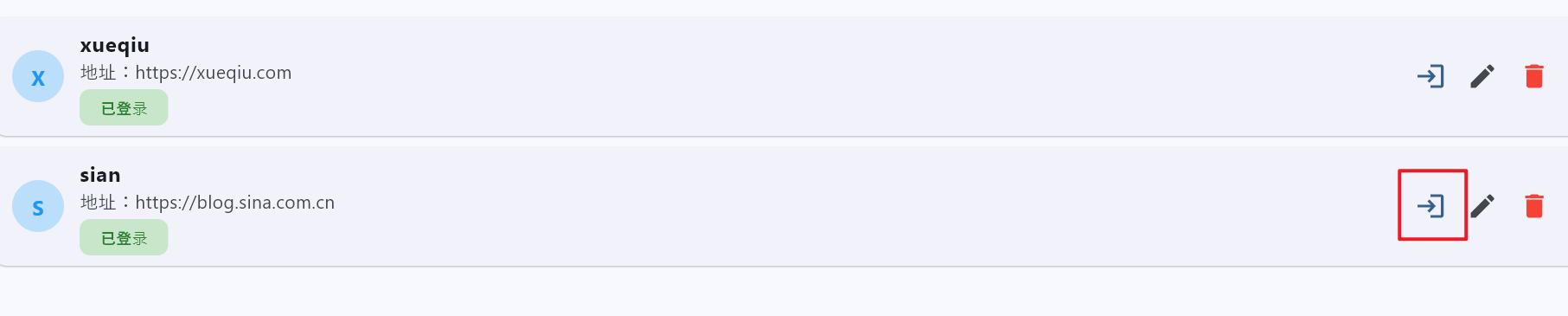
登录成功 后点下面 保存cookies
再次点
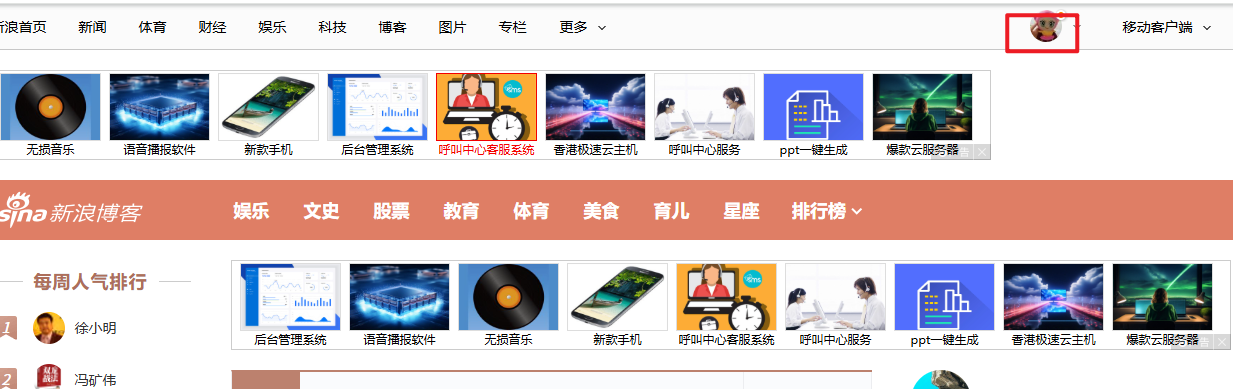
看打开的浏览器中,有没有显示自己头像
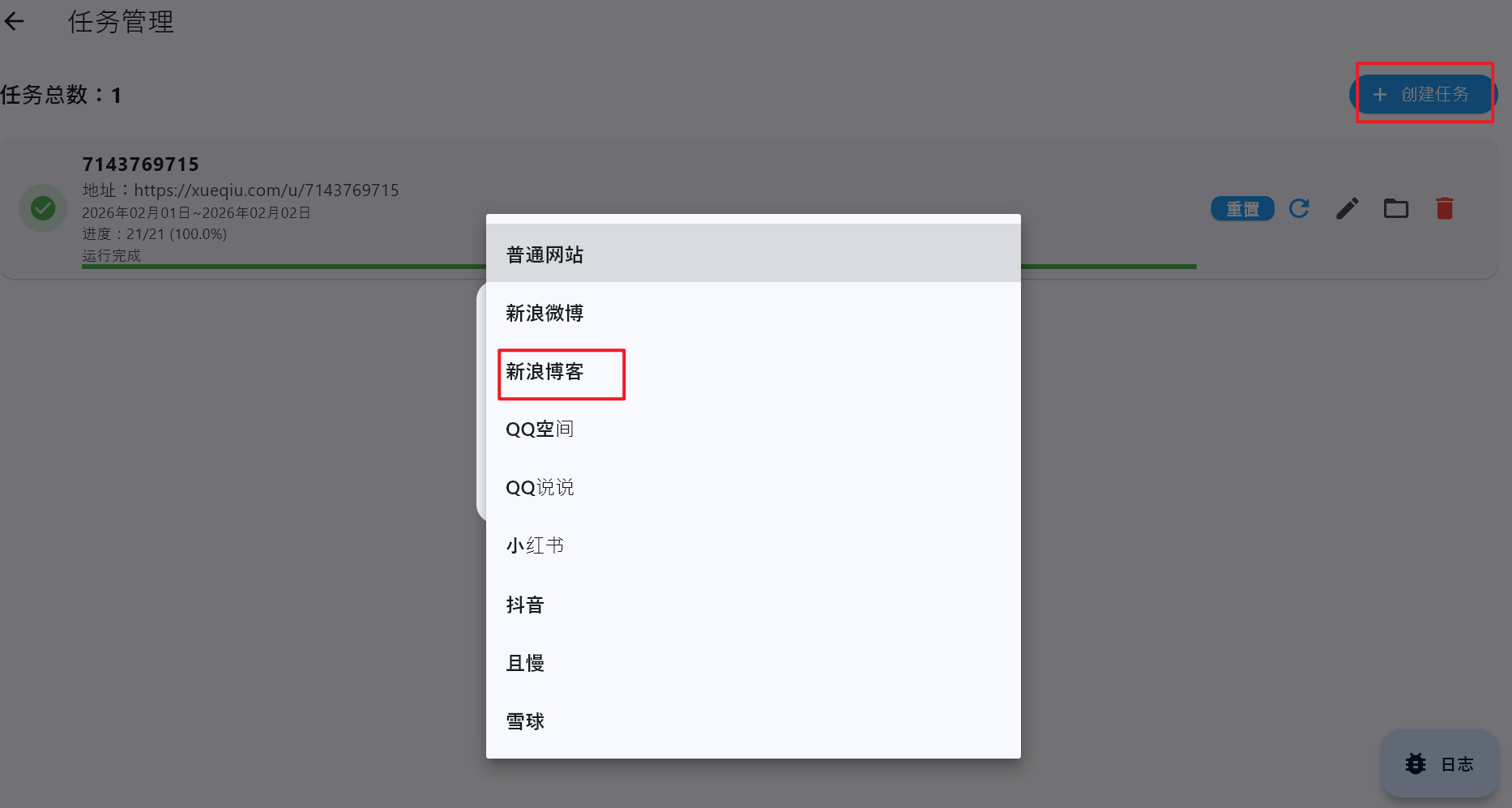
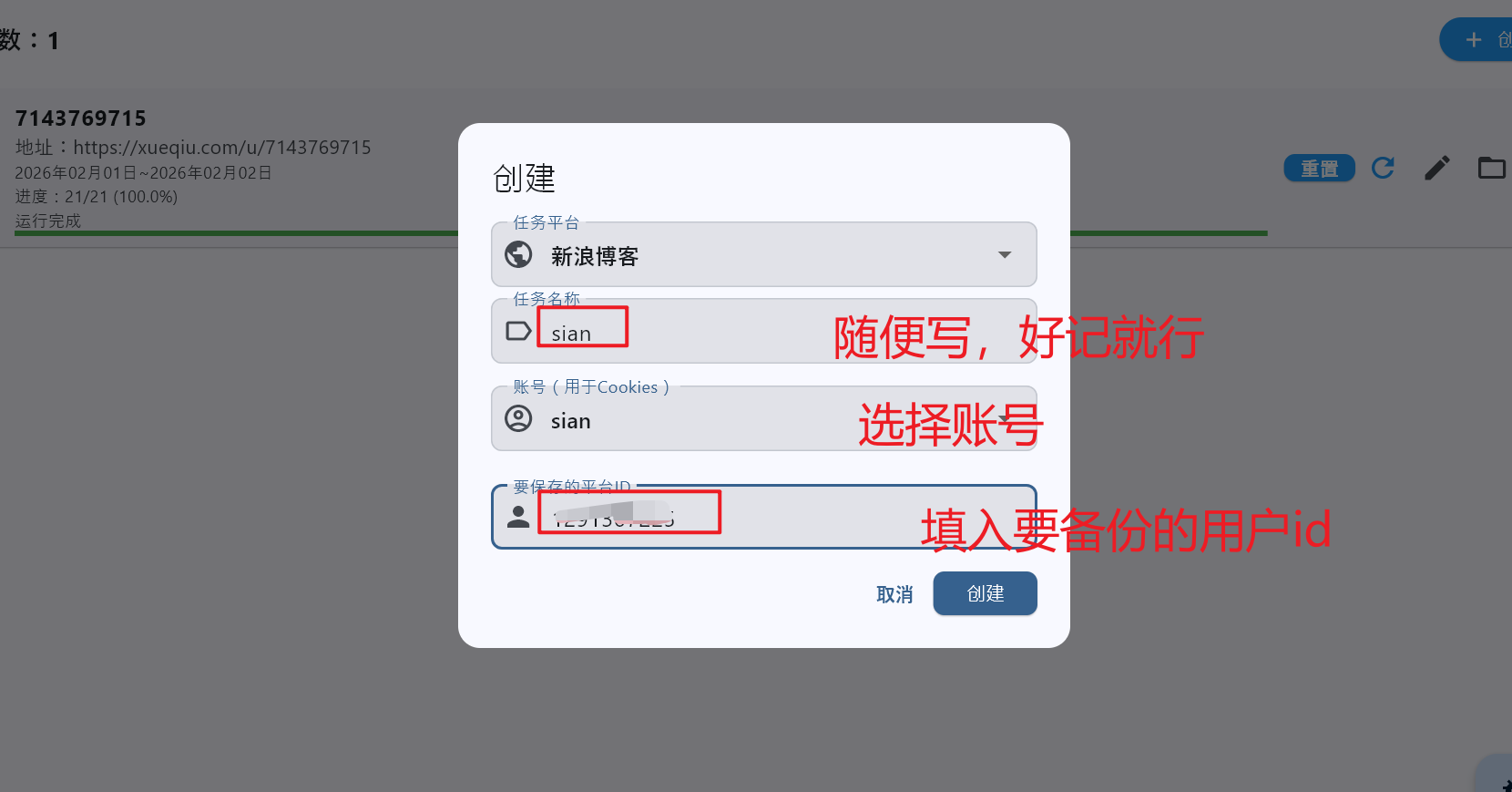
现在可以新建任务 了
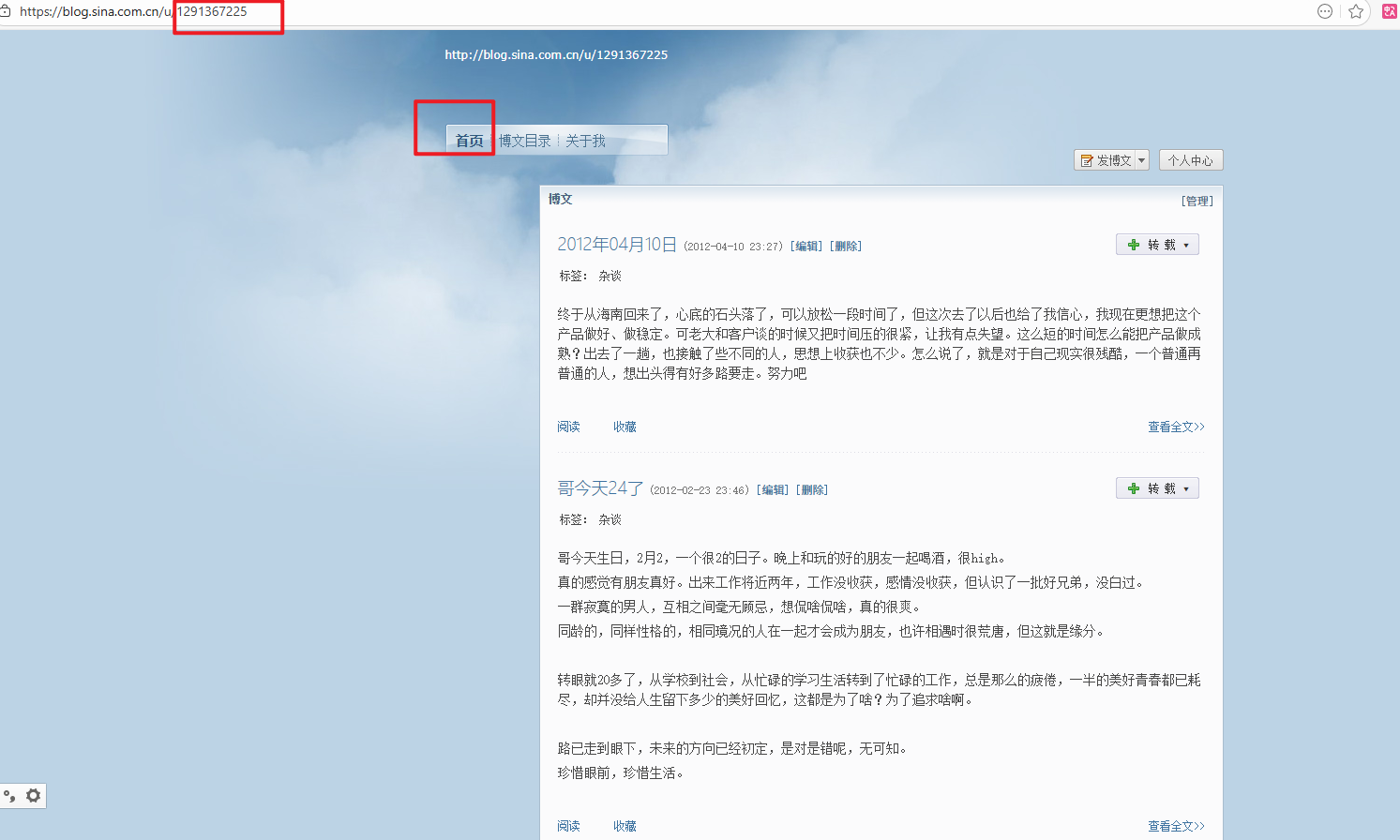
先打开你要备份用户的新浪博客首页
看网址后面数字就是id