1. 资料:
https://docs.ultralytics.com/zh#yolo-a-brief-history
https://github.com/ultralytics/ultralytics
yolov1: https://arxiv.org/abs/1506.02640
yolov2:https://arxiv.org/abs/1612.08242
yolov3: https://arxiv.org/abs/1804.02767
yolov7:https://arxiv.org/abs/2207.02696
2. 一些知识
2.1 四种图像处理
2.1.1 Detect
检测,主要是检测出图像中的一些特征,将将其框出来
2.1.2 Segment
分割,是用于将图像中不同类型抠出来。主要用于抠图,需要能分离出边界
2.1.3 Classify
分类,是针对整张图片。
2.1.4 Pose
姿态估计
- 任务描述: 姿态估计是指识别图像中特定物体的关键点 (Keypoints) 的位置,并估计其姿态。
- 输出: 模型输出一组关键点坐标,每个关键点对应于物体上的一个特定部位。
- 示例:
- 人体姿态估计: 识别图像中人体的关键点,例如头部、肩膀、肘部、手腕、膝盖、脚踝等。
- 物体姿态估计: 识别图像中物体的关键点,例如汽车的四个角、椅子的四个腿等。
2.1.5 obb
任务描述: OBB 是一种用于描述物体方向的边界框。 与传统的矩形边界框 (Axis-Aligned Bounding Box, AABB) 不同,OBB 可以旋转,从而更准确地包围具有任意方向的物体。
输出: 模型输出 OBB 的参数,通常包括中心坐标 (x, y)、宽度 (w)、高度 (h) 和旋转角度 (θ)。
应用场景:
- 遥感图像: 检测建筑物、车辆等具有任意方向的物体。
- 文本检测: 检测倾斜的文本行。
- 工业检测: 检测表面缺陷、零件等。
常见模型: 基于 YOLO 或 Faster R-CNN 的 OBB 检测模型。
2.2 训练指标
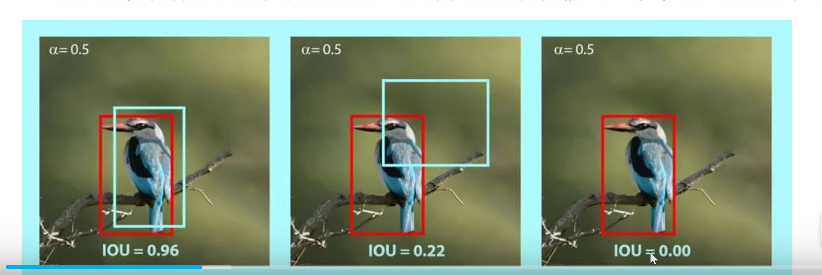
2.2.1 IOU
IoU 是 "Intersection over Union" 的缩写,中文译为 交并比,它是一种用于评估目标检测任务中,预测边界框 (predicted bounding box) 和真实边界框 (ground truth bounding box) 之间重叠程度的指标
IoU 的计算公式非常简单:
TEXT
IoU = (预测边界框 ∩ 真实边界框) / (预测边界框 ∪ 真实边界框)
2.2.2 map
我来详细解释 mAP (mean Average Precision) 的计算方法
AP 是针对单个类别计算的指标
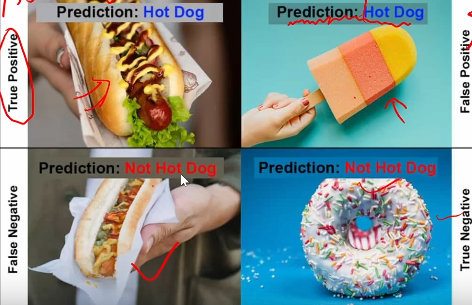
2.2.3 TP
正确的预测
给了框,框的位置对

2.2.4 FP
错误的预测
给了框,但是框的位置不对
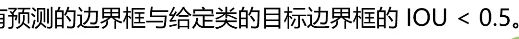
2.2.5 TN
正确的反例
应该没框,ai也没识别出框

2.2.6 FN
错误的反例
应该有框,但是没有预测出框
2.2.7 Precision (精确率):
2.2.8 Recall (召回率)
表示所有实际为正例的样本中,被模型正确预测为正例的比例。
Recall = TP / (TP + FN)
2.2.9 map
- 绘制 Precision-Recall 曲线:
- 将模型的预测结果按照置信度 (Confidence Score) 从高到低排序。
- 依次将每个预测结果作为阈值,计算对应的 Precision 和 Recall。
- 以 Recall 为横坐标,Precision 为纵坐标,绘制 Precision-Recall 曲线。
计算 AP:
- AP 是 Precision-Recall 曲线下的面积。
- Mean Average Precision (mAP) 的计算:
mAP 是针对多个类别计算的指标,它是所有类别的 AP 值的平均值。 计算 mAP 的步骤如下:
计算每个类别的 AP:
- 按照上述方法,计算每个类别的 AP 值。
计算 mAP:
- 将所有类别的 AP 值求平均,得到 mAP。
mAP = (AP<sub>1</sub> + AP<sub>2</sub> + ... + AP<sub>N</sub>) / N
2.3 yolo训练的参数
https://docs.ultralytics.com/modes/train/#resuming-interrupted-trainings
3. yoLov1
- vides the input image into an S × S grid,If the center of an object falls into a grid cell, that grid cell
is responsible for detecting that objec
- Each grid cell predicts B bounding boxes and confidence
scores for those boxes
- These confidence scores reflect how
confident the model is that the box contains an object and
also how accurate it thinks the box is that it predicts. For-
mally we define confidence as Pr(Object) ∗ IOU
- Each bounding box consists of 5 predictions: x, y, w, h,
and confidence
4. yolo源码
模型结构位置
cfg/models/11
5. 工具相关
5.1 查看模型
https://github.com/lutzroeder/netron